|
RMVL
2.1.0
Robotic Manipulation and Vision Library
|
载入中...
搜索中...
未找到
|
RMVL
2.1.0
Robotic Manipulation and Vision Library
|
涉及 Gauss-Newton 迭代 与 LM 非线性最小二乘求解算法
上一篇教程:最小二乘法 ↑
下一篇教程:非线性方程(组)数值解与迭代法 ↓
\[ \def\red#1{\color{red}{#1}} \def\teal#1{\color{teal}{#1}} \def\green#1{\color{green}{#1}} \def\transparent#1{\color{transparent}{#1}} \def\orange#1{\color{orange}{#1}} \def\Var{\mathrm{Var}} \def\Cov{\mathrm{Cov}} \def\tr{\mathrm{tr}} \def\fml#1{\text{(#1)}} \def\ptl#1#2{\frac{\partial#1}{\partial#2}} \]
数据处理中,最常见的一种函数形式是
\[f(\pmb x)=\frac12\sum_{i=1}^m\varphi_i^2(\pmb x)\tag{1-1}\]
如果 \(f(x)\) 的极小点 \(x^*\) 满足 \(f(x^*)< e\)( \(e\) 是预先给定的精度),那么可以认为 \(x^*\) 是 方程组
\[\varphi_i(x_1,x_2,\cdots,x_n)=0,\quad i=1,2,\cdots,m(m\ge n)\]
的解。
对式 \(\fml{1-1}\),可以用一阶导数运算来代替牛顿法中的二阶导数矩阵的求逆运算。因为
\[\begin{align}\nabla f(\pmb x)&=\begin{bmatrix} \sum\limits_{i=1}^m\ptl{\varphi_i(\pmb x)}{x_1}\varphi_i(\pmb x)\\ \sum\limits_{i=1}^m\ptl{\varphi_i(\pmb x)}{x_2}\varphi_i(\pmb x)\\ \vdots\\\sum\limits_{i=1}^m\ptl{\varphi_i(\pmb x)}{x_n}\varphi_i(\pmb x)\end{bmatrix}=\begin{bmatrix} \ptl{\varphi_1(\pmb x)}{x_1}&\ptl{\varphi_2(\pmb x)}{x_1}&\cdots&\ptl{\varphi_m(\pmb x)}{x_1}\\ \ptl{\varphi_1(\pmb x)}{x_2}&\ptl{\varphi_2(\pmb x)}{x_2}&\cdots&\ptl{\varphi_m(\pmb x)}{x_2}\\ \vdots&\vdots&\ddots&\vdots\\ \ptl{\varphi_1(\pmb x)}{x_n}&\ptl{\varphi_2(\pmb x)}{x_n}&\cdots&\ptl{\varphi_m(\pmb x)}{x_n} \end{bmatrix}\begin{bmatrix} \varphi_1(\pmb x)\\\varphi_2(\pmb x)\\\vdots\\\varphi_m(\pmb x)\end{bmatrix}\\ &=\pmb J^T(\pmb x)\pmb\varphi(\pmb x)\tag{1-2}\end{align}\]
式中, \(\pmb\varphi(\pmb x)\) 为 \(m\) 维的函数向量,即 \(\pmb\varphi(\pmb x)=[\varphi_1(x),\varphi_2(x),\cdots,\varphi_m(x)]^T\); \(\pmb J(\pmb x)\) 为函数 \(\pmb\varphi(\pmb x)\ (i=1,2,\cdots,m)\) 一阶偏导数组成的矩阵,即
\[\pmb J(\pmb x)=\begin{bmatrix} \ptl{\varphi_1(\pmb x)}{x_1}&\ptl{\varphi_1(\pmb x)}{x_2}&\cdots&\ptl{\varphi_1(\pmb x)}{x_n}\\ \ptl{\varphi_2(\pmb x)}{x_1}&\ptl{\varphi_2(\pmb x)}{x_2}&\cdots&\ptl{\varphi_2(\pmb x)}{x_n}\\ \vdots&\vdots&\ddots&\vdots\\ \ptl{\varphi_m(\pmb x)}{x_1}&\ptl{\varphi_m(\pmb x)}{x_2}&\cdots&\ptl{\varphi_m(\pmb x)}{x_n} \end{bmatrix}\tag{1-3}\]
特别当 \(\pmb\varphi(\pmb x)\) 是 \(\pmb x\) 的线性函数时,式 \(\fml{1-2}\) 中的 \(\pmb J(\pmb x)\) 是常系数矩阵。这时式 \(\fml{1-1}\) 的海赛矩阵可以写成
\[\pmb H=\pmb J^T\pmb J\tag{1-4}\]
这样,关于 \(\pmb\varphi(\pmb x)\) 是 \(\pmb x\) 的线性函数时的最小二乘法的迭代公式可以写为
\[\pmb x_{k+1}=\pmb x_k-\pmb H^{-1}(\pmb x_k)\pmb J^T(\pmb x_k)\pmb\varphi(\pmb x_k)\tag{1-5}\]
当 \(\pmb\varphi(\pmb x)\) 不是 \(\pmb x\) 的线性函数时,也可以近似将式 \(\fml{1-4}\) 视为函数 \(f(\pmb x)\) 的海赛矩阵,即
\[\pmb H\approx\left[\pmb J(\pmb x_k)\right]^T\pmb J(\pmb x_k)\tag{1-6}\]
所以,关于 \(\pmb\varphi(\pmb x)\) 不是 \(\pmb x\) 的线性函数时的最小二乘法的迭代公式也可以写为 \(\fml{1-5}\) 的形式。
\[\Delta\pmb x_0=-\pmb H_0^{-1}\pmb J_0^T\pmb\varphi(\pmb x_k)\tag{1-6}\]
\[\pmb x_1=\pmb x_0+\Delta\pmb x_0\tag{1-7}\]
\[\|\pmb\varphi(\pmb x_k)\|<\epsilon'\tag{1-8a}\]
或\[\|\nabla f(\pmb x_k)\|<\epsilon''\tag{1-8b}\]
为止。 \(\epsilon'\) 和 \(\epsilon''\) 是预先给定的精度。上述高斯-牛顿最小二乘法利用了目标函数在极小值处近似为自变量各分量的平方和的特点,用 \(\pmb J^T\pmb J\) 近似代替牛顿法中 \(f(\pmb x)\) 的二阶导数矩阵,大大节省了计算量。但是它对初始点 \(\pmb x_0\) 的要求比较严格,如果初始点 \(\pmb x_0\) 与极小点 \(\pmb x^*\) 相距很远,这个算法往往失败。原因是
为此采取下述改进的办法。在求出 \(\pmb x_k\) 的校正量 \(\Delta\pmb x_k\) 后,不把 \(\pmb x_k+\Delta\pmb x_k\) 作为第 \(k+1\) 次近似点,而是将 \(\Delta\pmb x_k\) 作为下一步的一维方向搜索。求 \(\alpha_k\),使
\[f(\pmb x_k+\alpha_k\pmb s_k)=\min_{\alpha>0}f(\pmb x_k+\alpha\pmb s_k)\]
然后令
\[\pmb x_{k+1}=\pmb x_k+\alpha_k\pmb s_k\]
以 \(\pmb x_{k+1}\) 代替 \(\pmb x_k\) 重复上述计算过程,直到 \(\|\pmb\varphi(\pmb x_k)\|<\epsilon'\) 或 \(\|\nabla f(\pmb x_k)\|<\epsilon"\) 为止。
RMVL 提供了改进的 Gauss-Newton 迭代算法,可参考 rm::lsqnonlin 函数。例如,我们需要拟合一个正弦函数
\[y=A\sin(\omega t+\varphi_0)+b\]
其中, \(A,\omega,\varphi_0,b\) 是待拟合的参数,不妨统一写为 \(\pmb x=(A,\omega,\varphi_0,b)\),也就是说我们需要拟合的函数是
\[\green y=x_1\sin(x_2\green t+x_3)+x_4\]
其中 \(t\) 和 \(y\) 是可以观测到的数据,我们需要通过观测的数据来拟合 \(\pmb x\) 的值。比方说,下面的 obtain 函数就可以观测每一帧的数据。
例如经过了 20 帧的数据采集,我们得到了一个长度为 20 的队列,即
准备好数据后,可以使用下面的代码来拟合正弦函数。
普通的 Gauss-Newton 迭代,在初始值附近做了一阶线性化处理,而当初始值与极小值相差较远时,曲线的非线性特性会导致迭代失败。为了解决这个问题,Levenberg–Marquardt 算法在 Gauss-Newton 迭代的基础上,引入了一个参数 \(\lambda\),使得迭代公式变为
\[\pmb x_{k+1}=\pmb x_k-\left(\pmb J^T\pmb J+\red{\lambda\pmb I}\right)^{-1}\pmb J^T\pmb\varphi(\pmb x_k)\tag{2-1}\]
\(I\) 是单位矩阵, \(\lambda\) 是一个非负数。如果 \(\lambda\) 取值较大时, \(\lambda I\) 占主要地位,此时的 LM 算法更接近一阶梯度下降法,说明此时距离最终解还比较远,用一阶近似更合适。反之,如果 \(\lambda\) 取值较小时, \(\pmb H=\pmb J^T\pmb J\) 占主要地位,说明此时距离最终解距离较近,用二阶近似模型比较合适,可以避免梯度下降的震荡,容易快速收敛到极值点。因此参数 \(\lambda\) 不仅影响到迭代的方向还影响到迭代步长的大小。
令初值为 \(\pmb x_0\),可以设置 \(\lambda\) 的初值 \(\lambda_0\) 为
\[\begin{align}\pmb A_0&=\pmb J^T(\pmb x_0)\pmb J(\pmb x_0)\\ \lambda_0&=\tau\max_i\left\{a_{ii}^{(0)}\right\}\end{align}\tag{2-2}\]
其中, \(\tau\) 可以自己指定, \(a_{ii}\) 表示矩阵 \(\pmb A\) 对角线元素。此外, \(\lambda\) 需要在迭代过程中不断调整,以保证迭代的收敛性。一般会判断近似的模型与实际函数之间的差异,可以使用下面的公式来判断
\[\rho_k=\frac{f(\pmb x_k+\Delta\pmb x_k)-f(\pmb x_k)}{\pmb J(\pmb x_k)\Delta\pmb x_k}\tag{2-3}\]
\[\lambda_{k+1}=\frac{\lambda_k}2\]
\[\lambda_{k+1}=2\lambda_k\]
\[\pmb x_{k+1}=\pmb x_k\]
并且和上面 \(\rho_k\le0.25\) 的情况一样,减小 \(\lambda_k\),反之,在 \(\rho_k>0\) 的情况下,更新 \(\pmb x_k\),即\[\pmb x_{k+1}=\pmb x_k\]
还是上面的例子,我们可以使用下面的代码来拟合正弦函数。
鲁棒核函数(Robust Kernel Function)是在优化问题中用来减少离群值(outliers)影响的一种技术。在 Bundle Adjustment (BA) 等计算机视觉问题中,鲁棒核函数特别有用,因为这些问题常常受到错误匹配、遮挡或其他因素导致的离群值影响
标准的最小二乘优化问题可以表示为:
\[\min_{\pmb x}\sum_i\frac12\|e_i(\pmb x)\|^2\tag{3-1}\]
其中 \(e_i(x)\) 是第 \(i\) 个观测的误差。引入鲁棒核函数后,优化问题变为:
\[\min_{\pmb x}\sum_i\rho(e_i(\pmb x))\tag{3-2}\]
其中 \(\rho(s)\) 是鲁棒核函数。鲁棒核函数主要有
的特点,常用的鲁棒核函数是 Huber 损失函数:
\[\rho(s)=\begin{cases}\frac12s^2&\quad|s|\leq k\\k(|s|-\frac12k)&\quad|s|>k\end{cases}\tag{3-3}\]
当 \(k=1\) 时,Huber 核函数的图像如下图所示。
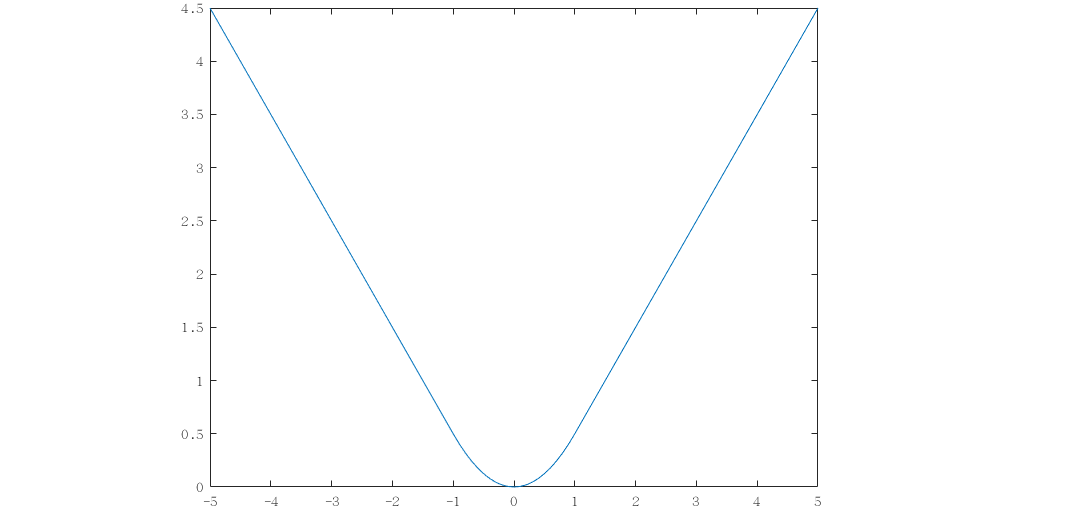
Huber 核函数是一个连续可导的函数,它的优点是它在 \(s=0\) 附近是二次的,这使得它对小误差的敏感度与标准二次函数相似,而对大误差的敏感度较低,减少了它们的影响。对于 \(\fml{3-2}\) 式这一新的最优化目标函数,按照一般想法,求解其导数的零点,便能得到最优解。
\[\begin{align}f(\pmb x)&=\sum_{i=1}^m\rho(e_i)\\\ptl{f(\pmb x)}{\pmb x}&=\sum_{i=1}^m\ptl{\rho(e_i)}{\pmb x}=\sum_{i=1}^m\rho'(e_i)\ptl{e_i(\pmb x)}{\pmb x}\\&=\begin{bmatrix}\sum\limits_{i=1}^m\rho'(e_i)\ptl{e_i}{x_1}\\\sum\limits_{i=1}^m\rho'(e_i)\ptl{e_i}{x_2}\\\vdots\\\sum\limits_{i=1}^m\rho'(e_i)\ptl{e_i}{x_n}\end{bmatrix}=\pmb J^T\begin{bmatrix}\rho'(e_1)\\\rho'(e_2)\\\vdots\\\rho'(e_m)\end{bmatrix}\stackrel{\triangle}{=}\pmb J^T\pmb\rho'=0\tag{3-4}\end{align}\]
对于加权最小二乘问题,目标函数形如
\[f(\pmb x)=\frac12\sum_{i=1}^mw_ie_i^2(\pmb x)\tag{3-5}\]
同样求解其导数的零点,能得到加权最小二乘问题的最优解。
\[\ptl{f(\pmb x)}{\pmb x}=\sum_{i=1}^mw_ie_i(\pmb x)\ptl{e_i(\pmb x)}{\pmb x}=\pmb J^T\begin{bmatrix}w_1e_1(\pmb x)\\w_2e_2(\pmb x)\\\vdots\\w_me_m(\pmb x)\end{bmatrix}\stackrel{\triangle}{=}\pmb J^T\pmb{We}\tag{3-6}\]
其中 \(\pmb W\) 是以 \(w_i\) 为对角元的对角矩阵。
对比 \(\fml{3-4}\) 式和 \(\fml{3-6}\) 式,我们希望 Huber 核函数的最优化问题能够转换为加权最小二乘问题,即
\[\begin{align}\pmb{We}&=\pmb\rho'\\w_ie_i(\pmb x)&=\rho'(e_i)\quad i=1,2,\cdots,m\end{align}\tag{3-7}\]
因此 \(w_i\)可以定义为
\[w_i=\frac{\rho'(e_i)}{e_i}\tag{3-8}\]
这样,我们就可以将 Huber 核函数的最优化问题转换为加权最小二乘问题。
对于 Huber 损失函数,我们有
\[\rho'(e_i)=\begin{cases}e_i&|e_i|\leq k\\k\cdot\texttt{sgn}(e_i)&|e_i|>k\end{cases}\tag{3-9}\]
其中, \(\texttt{sgn}\)为符号函数,可参考 rm::sgn 。因此,权重 \(w_i\)为
\[w_i=\frac{\rho'(e_i)}{e_i}=\begin{cases}1&|e_i|\leq k\\\frac{k}{|e_i|}&|e_i|>k\end{cases}\tag{3-10}\]
这有比较明确的物理意义
此时 \(\Delta\pmb x_k\)搜索方向的计算可以改为
\[\Delta\pmb x_k=-\left(\pmb J^T\pmb W\pmb J\right)^{-1}\pmb J^T\pmb W\pmb e\tag{3-11a}\]
Levenberg–Marquardt 算法的迭代公式也可以改为
\[\pmb x_{k+1}=\pmb x_k-\left(\pmb J^T\pmb W\pmb J+\lambda\pmb I\right)^{-1}\pmb J^T\pmb W\pmb e\tag{3-11b}\]
在实际应用中,通常取 \(\rho(s)=\rho\left(\frac{e_1}\sigma\right)\),而并不直接使用 \(\rho(e_i)\),其中 \(\sigma\) 一般使用中位绝对偏差(MAD)来估计,以保证不过分受异常值的影响。可使用一下公式来计算 \(\sigma\):
\[\hat\sigma=1.4826\times\text{median}\left\{|e_i-\text{median}(e_i)|\right\}\tag{3-12}\]
常用的 Robust 核函数及其权重如下表所示。
| \(\rho(s)\) | \(\rho'(s)\) | \(w_i=\frac{\rho'(s)}{s}\) | |
|---|---|---|---|
| L2 | \(\frac12s^2\) | \(s\) | \(1\) |
| Huber | \[\begin{cases}\frac12s^2&\vert s\vert\leq k\\k(\vert s\vert-\frac12k)&\vert s\vert>k\end{cases}\] | \[\begin{cases}s&\vert s\vert\leq k\\k\cdot\texttt{sgn}(s)&\vert s\vert>k\end{cases}\] | \[\begin{cases}1&\vert s\vert\leq k\\\frac{k}{\vert s\vert}&\vert s\vert>k\end{cases}\] |
| Tukey | \[\begin{cases}\frac{k^2}{6}\left[1-\left(1-\frac{s^2}{k^2}\right)^3\right]&\vert s\vert\leq k\\\frac{k^2}{6}&\vert s\vert>k\end{cases}\] | \[\begin{cases}s\left(1-\frac{s^2}{k^2}\right)^2&\vert s\vert\leq k\\0&\vert s\vert>k\end{cases}\] | \[\begin{cases}\left(1-\frac{s^2}{k^2}\right)^2&\vert s\vert\leq k\\0&\vert s\vert>k\end{cases}\] |
| GM | \[\frac{s^2}{2\left(1+s^2\right)}\] | \[\frac{s}{\left(1+s^2\right)^2}\] | \[\frac{1}{\left(1+s^2\right)^2}\] |
| Cauchy | \[\frac{c^2}2\log\left[1+\left(\frac sk\right)^2\right]\] | \[\frac{s}{1+\left(\frac{s}{k}\right)^2}\] | \[\frac{1}{1+\left(\frac{s}{k}\right)^2}\] |
不难发现,L2 核函数就是原来的目标函数 \(\fml{3-1}\)。在正态分布的假设下
RMVL 提供了带有 Robust 核函数的最小二乘法,可参考 rm::lsqnonlinRKF ,对于上面示例中的正弦函数拟合,可以使用下面的代码。
 1.12.0
1.12.0